You don’t pass a data engineer interview by listing tools. You pass by proving you can move data reliably, at scale, without blowing up cost, and without lying to downstream teams.
This article gives you the data engineer interview questions you’ll face in 2026 that focus on the core skills: strong SQL, practical Python, distributed processing (Spark), orchestration (Airflow), streaming (Kafka), cloud fundamentals, and system design trade-offs and the rubric interviewers score you on, plus answer patterns that don’t sound rehearsed.
Table of Contents
How data engineer interviews work in 2026
Most data engineer interviews follow a predictable loop. The names of tools change by company, but the evaluated skills stay consistent.
1) Recruiter / hiring manager screen (30–45 min)
They’re not testing depth. They’re testing:
- Can you explain your last pipeline clearly?
- Do you understand why choices were made (not just “we used Spark”)?
- Can you talk about failures without excuses?
Gotcha: If you can’t describe input → transformations → output → SLA → data quality → backfill strategy, you’re not ready.
2) SQL + Python technical screens (45–60 min each)
- SQL: windows, dedup, incremental loads, CDC/SCD2, debugging wrong counts.
- Business metrics (retention, funnels, DAU/WAU/MAU)
- Python: parsing, batching, idempotency, memory, correctness under retries.
Gotcha: Most candidates lose points on edge cases, not syntax.
3) System design (60–90 min)
You design a pipeline or platform component. Interviewers grade:
- contracts, SLAs, failure modes
- incremental strategy
- schema evolution
- observability + cost
Gotcha: “We’ll just replay everything” is not a strategy. Backfills need guardrails.
4) One “tools” round (Spark/Airflow/Kafka/dbt/warehouse)
This is usually scenario-based:
- performance debugging
- orchestration correctness
- streaming semantics (late events, exactly-once illusions)
- warehouse/lakehouse modeling decisions
5) Behavioral / collaboration (30–60 min)
Data engineering is cross-functional pain. They want proof you can:
- handle ambiguous requirements
- push back on bad asks
- keep pipelines stable during change
How to answer like a strong candidate
Use a consistent structure:
- clarify assumptions
- propose approach
- discuss edge cases
- estimate complexity
- mention production concerns.
The scoring rubric interviewers use
Interviewers rarely grade with one yes/no checkbox. They score multiple dimensions, often subconsciously.
Rubric dimension 1: Correctness (baseline)
You must produce correct results for:
- typical inputs
- edge cases
- “dirty data” (nulls, malformed rows, duplicates)
How to signal correctness fast
- State assumptions explicitly (“timestamps are epoch seconds”)
- Add validations (“skip records missing user_id”)
- Provide a small example and walk through output
Rubric dimension 2: Data engineering thinking (the differentiator)
They look for production instincts:
- Idempotency: safe to retry and re-run
- Determinism: consistent output ordering/behavior
- Observability: logs, metrics, and failure visibility
- Backfills: ability to recompute safely for a date range
Rubric dimension 3: Performance and scale awareness
You don’t need to “over-optimize,” but you must reason about:
- time complexity
- memory usage
- partitioning/shuffles (Spark)
- expensive operations (wide joins, full table scans)
Rubric dimension 4: Communication
Clear, structured answers win:
- talk through steps
- name trade-offs
- keep queries readable
- keep code modular
Rubric dimension 5: Tool fluency (without tool worship)
Strong candidates treat tools as implementations of principles:
- Airflow = orchestration + retries/backfills
- Spark = distributed execution + shuffles/partitions
- Kafka = ordered partitions + consumer groups + replay
The fastest way to answer ANY DE interview question (the “4-step” pattern)
When you’re stuck, do this:
- Clarify grain + keys
- List edge cases (duplicates, late data, nulls, deletes)
- Pick the simplest correct approach
- Add scale + reliability upgrades (partitioning, idempotency, observability)
This makes you sound senior even when the question is basic.
SQL Data Engineer Interview Questions
What’s the difference between INNER JOIN, LEFT JOIN, and FULL OUTER JOIN?
Answer:
- INNER JOIN returns only matching rows.
- LEFT JOIN keeps all left rows and matches right rows when possible (null if missing).
- FULL OUTER JOIN returns all rows from both sides with nulls where unmatched.
Interview tip: Mention where you’d use each in pipelines (enrichment, reconciliation, completeness checks).
How do you find duplicate rows by business key?
Answer: Group by the business key and filter COUNT(*) > 1.
SELECT user_id, event_id, COUNT(*) AS cnt
FROM events
GROUP BY user_id, event_id
HAVING COUNT(*) > 1;
How do you keep only the latest record per key?
Answer: Use ROW_NUMBER() partitioned by the key and ordered by timestamp descending.
SELECT *
FROM (
SELECT
t.*,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY updated_at DESC) AS rn
FROM user_profile t
) x
WHERE rn = 1;
Common follow-up: “What if timestamps tie?”
Add a tie-breaker column like ingested_at or event_id.
ROW_NUMBER vs RANK vs DENSE_RANK?
Answer:
- ROW_NUMBER() assigns unique sequence numbers (no ties).
- RANK() gives same rank for ties and leaves gaps.
- DENSE_RANK() gives same rank for ties without gaps.
Get the latest record per user
What they’re testing: dedup strategy + tie-breaking + performance.
Answer (window function):
SELECT *
FROM (
SELECT
t.*,
ROW_NUMBER() OVER (
PARTITION BY user_id
ORDER BY updated_at DESC, event_id DESC
) AS rn
FROM events t
) x
WHERE rn = 1;
Gotcha to mention: If timestamps can tie, add a stable tie-breaker (event_id, ingestion_id).
Find users with gaps-and-islands (consecutive days)
What they’re testing: analytic thinking.
Answer (classic trick):
WITH d AS (
SELECT user_id, activity_date,
DATEADD(day, -ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY activity_date), activity_date) AS grp
FROM activity
)
SELECT user_id, MIN(activity_date) AS start_date, MAX(activity_date) AS end_date, COUNT(*) AS days
FROM d
GROUP BY user_id, grp;
Sessionize events with 30-minute inactivity
Answer (lag + sum):
WITH x AS (
SELECT *,
CASE WHEN TIMESTAMPDIFF(minute,
LAG(event_ts) OVER (PARTITION BY user_id ORDER BY event_ts),
event_ts
) > 30 THEN 1 ELSE 0 END AS new_session
FROM web_events
),
y AS (
SELECT *,
SUM(new_session) OVER (PARTITION BY user_id ORDER BY event_ts) AS session_id
FROM x
)
SELECT user_id, session_id,
MIN(event_ts) AS session_start,
MAX(event_ts) AS session_end,
COUNT(*) AS events
FROM y
GROUP BY user_id, session_id;
Gotcha: “Exactly 30 minutes” edge case-clarify whether boundary starts a new session.
Incremental load: load only new/changed rows
Best answer: Use high-watermark or CDC, depending on source guarantees.
- If you have a reliable
updated_at: watermark byupdated_at - If updates can arrive late/out-of-order: use CDC or store a hash and re-check a lookback window
Gotcha: Always add a lookback window unless you can prove strict monotonicity.
SCD Type 2 for dimension updates
Answer (conceptual):
- Natural key: customer_id
- Version columns: valid_from, valid_to, is_current
- On change: expire current row, insert new row
Gotcha: Handle no-op updates (same values) or you’ll create fake history.
Why do counts not match between source and warehouse?
Senior answer checklist:
- duplicates in source / replays
- join explosion (many-to-many)
- timezone truncation differences
- late data excluded by watermark
- filters applied in different places
- distinct vs count(*) mismatch due to grain confusion
Read Next: Tricky SQL Queries for Interview
Python Data Engineer Interview Questions
Flatten nested JSON
What they test: recursion + schema variability.
def flatten(d, prefix=""):
out = {}
for k, v in d.items():
key = f"{prefix}.{k}" if prefix else k
if isinstance(v, dict):
out.update(flatten(v, key))
else:
out[key] = v
return out
Gotcha: Arrays. Decide whether to explode them or keep JSON strings.
Make this ETL idempotent
Best answer: Idempotency is not a vibe. It’s a mechanism:
- deterministic primary keys
- upserts/merge by key
- write to temp + atomic swap
- exactly-once is usually achieved through dedup + merge, not magic
Read a 200GB file – don’t OOM
Correct answer: stream/chunk.
import csv
def iter_rows(path):
with open(path, newline="") as f:
reader = csv.DictReader(f)
for row in reader:
yield row
Gotcha: If you “just pandas.read_csv”, you fail.
How do you read large files without running out of memory?
Answer: Stream input in chunks or line-by-line, and process incrementally.
def read_lines(path):
with open(path, “r”, encoding=”utf-8″) as f:
for line in f:
yield line.rstrip(“\n”)
Retries: how do you avoid double-writing?
Answer:
- Use write-ahead state (checkpoint table) or merge by key
- Make writes atomic (staging + rename, transactional table formats)
- Store a run_id and enforce uniqueness
What tests matter for pipelines?
Answer that scores:
- unit tests for transforms
- contract tests for schema + nullability + constraints
- integration test for one small run end-to-end
- data quality checks in prod (tests are not enough)
What’s idempotency in Python ETL terms?
Answer:
Running the job twice should not double-count or duplicate outputs. Use deterministic keys, overwrite-per-partition, or upserts.
List vs generator: what’s the difference and why does it matter?
Answer:
Lists hold everything in memory; generators yield items lazily. Generators are ideal for large ETL inputs and streaming transformations.
Spark / distributed processing questions for Data Engineer
What causes a shuffle? How do you reduce it?
Answer: joins, groupBy, distinct, repartition. Reduce by:
- broadcast small tables
- pre-aggregate
- partition by join keys
- avoid wide transformations
Gotcha: Repartitioning blindly can increase shuffle cost.
Explain data skew and how to fix it
Strong fixes:
- salting hot keys
- skew hints (when available)
- split hot keys into separate path
- two-stage aggregation (partial then final)
Gotcha: Broadcast join doesn’t fix skew if the other side is skewed.
Caching: when is it bad?
Answer: caching helps only when:
- reused multiple times
- dataset fits in memory
- you control lineage blowups
Gotcha: Caching a huge dataset triggers eviction thrash and kills performance.
Parquet/Delta small files problem
Answer: Too many small files increases planning overhead and read amplification. Fix:
- compaction jobs
- optimize/auto-compaction features (format-dependent)
- correct partition sizing
Repartition vs coalesce: what’s the difference?
Answer:
- repartition(n) reshuffles data to create evenly balanced partitions (more expensive).
- coalesce(n) reduces partitions without a full shuffle when possible (cheaper, but may create imbalance).
What is data skew and how do you spot it?
Answer: Skew happens when certain keys dominate (e.g., one customer has 80% of events), causing stragglers and long stages. Spot it via:
- skewed key distribution metrics
- long tails in stage duration
- huge partition sizes for certain keys
Airflow / orchestration questions
How do you design a backfill safely?
Answer:
- parameterize by partition/date
- isolate side effects (write per partition)
- throttle concurrency
- enforce idempotency
- run data quality checks per partition
Gotcha: Backfills can DDOS your warehouse if you don’t cap concurrency.
What is a DAG in Airflow?
Answer: A DAG is a directed acyclic graph representing task dependencies and execution order. In DE pipelines, DAGs define ingestion, transformation, validation, and publishing steps.
What makes a DAG maintainable?
Answer:
- small tasks with clear contracts
- retries + timeouts with intent
- alerting that’s actionable
- sensors avoided or tuned (don’t block workers forever)
What is idempotency and why does it matter in orchestration?
Answer:
Idempotent tasks produce the same output even if retried or rerun. It’s essential for safe retries, backfills, and partial failures.
How do you monitor an Airflow pipeline in production?
Answer:
- SLA alerts (late runs)
- task failure alerts + error budgets
- metrics: row counts, null rates, freshness
- logs with correlation IDs (dag_id/run_id)
- dashboards: success rate, runtime, lag
Streaming (Kafka) Data Engineer Interview Questions
Event time vs processing time
Answer:
- event time = when it happened
- processing time = when you saw it
- late events require watermarks + retractions or compensating logic
Gotcha: “We’ll just use processing time” breaks analytics correctness.
What is a Kafka topic and partition?
Answer:
A topic is a named stream of records. Partitions split the topic into ordered logs that enable parallelism; ordering is guaranteed within a partition.
What is a consumer group?
Answer:
A consumer group is multiple consumers sharing work. Kafka assigns partitions to consumers within the group so they can process in parallel.
How do you handle out-of-order events?
Answer:
- process by event time, not ingestion time
- allow a lateness window (watermarking concept)
- use upserts in your serving layer
- design “corrections” (retractions/updates) downstream
How do you avoid duplicates in streaming pipelines?
Answer:
Use deterministic event IDs, idempotent writes, and de-dup windows keyed by (entity_id, event_id). If duplicates can arrive days later, persist a dedup key store with TTL.
Exactly-once delivery – real or marketing?
Answer:
Exactly-once is usually end-to-end semantics, not a single knob. You still need:
- deterministic keys
- deduplication
- transactional sinks or merge
Data modeling + warehouse/lakehouse questions (2026)
What’s the grain of your fact table?
Answer: The grain is the unique event/unit your fact represents. Define it before writing SQL.
Gotcha: Grain confusion causes “counts don’t match” and join explosions.
Star schema vs wide table
Answer:
- star schema: stable, scalable, reusable
- wide table: faster for single use-case, risk of duplication + inconsistency
Star schema vs snowflake schema
Answer:
Star schemas denormalize dimensions for simpler queries; snowflake schemas normalize dimensions to reduce redundancy at the cost of extra joins.
Fact vs dimension tables
Answer:
- Facts store measurable events (orders, clicks, payments).
- Dimensions store descriptive attributes (customer, product, campaign).
What is an OLAP vs OLTP workload?
Answer:
OLTP focuses on fast transactions and updates; OLAP focuses on analytical queries across large history with scans, aggregates, and joins.
What is a lakehouse (practically)?
Answer:
A lakehouse stores data in object storage like a lake but adds warehouse-like features: table management, schema enforcement, and reliable reads/writes for analytics.
How do you design tables for performance?
Answer:
- choose columnar formats (Parquet/ORC) when possible
- partition by common filters (event_date, tenant_id)
- avoid too many tiny files (compact)
- cluster/sort by high-cardinality filters if supported
- keep grain clear (one row per entity per time)
Data quality: what checks do you implement?
Answer:
- schema checks (expected columns/types)
- completeness checks (row counts, missing partitions)
- validity checks (ranges, allowed values)
- uniqueness checks (keys)
- freshness checks (data not late)
- reconciliation checks (source vs target totals)
Cloud + cost/security questions (2026)
How do you reduce warehouse costs?
Strong answer list:
- partition pruning / clustering
- reduce scans with incremental models
- pre-aggregate for common queries
- stop runaway queries (governance)
- right-size compute, schedule heavy jobs off-peak
How do you handle PII?
Answer:
- classify PII fields
- least privilege access
- masking/tokenization where needed
- audit access
- avoid copying PII into “convenience” tables
Gotcha: “We’ll just lock the bucket” is not a plan.
What are “small files” and why do they hurt?
Answer:
Too many small files increase metadata overhead and slow down reads in object storage-based systems. Compaction improves scan efficiency and reduces planning time.
What is least privilege?
Answer:
Least privilege means users and services only get the minimum permissions needed. It limits blast radius if credentials leak.
How do you design for failures in cloud?
Answer:
- retries with backoff for transient failures
- idempotent outputs for safe re-runs
- checkpoints for streaming jobs
- dead-letter queues for bad events
- alerts on error rates and lag
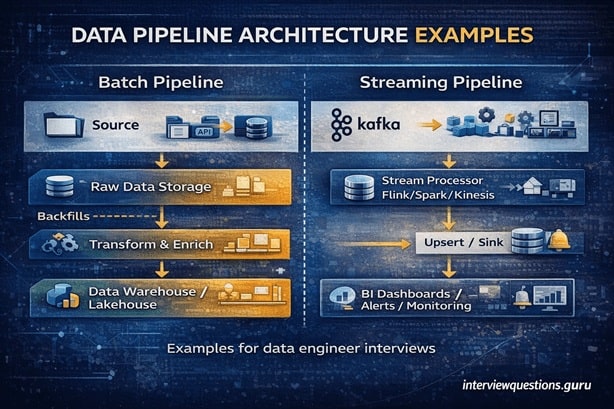
System design: the 6-layer framework (interview-proof)
Use this framework to answer almost any data engineering system design prompt (batch or streaming). It keeps you structured and interviewers love structure.
Layer 1: Ingestion
- batch: files, APIs, database extracts, CDC logs
- streaming: Kafka topics, event buses
Key questions: volume, latency, schema, duplication rate
Layer 2: Raw storage (immutable)
- object storage or raw tables
- store exact source payloads (for replay)
Key questions: retention, partitioning, encryption
Layer 3: Processing / transformation
- Spark jobs, SQL transforms, dbt models
- validate, clean, enrich, deduplicate
Key questions: incremental vs full refresh, compute cost
Layer 4: Serving layer
- warehouse/lakehouse tables
- marts for BI, feature tables for ML
Key questions: query patterns, SLA, concurrency
Layer 5: Orchestration
- scheduling, dependencies, retries
- backfills, versioning, CI/CD for data changes
Key questions: idempotency, data interval logic
Layer 6: Reliability + governance
- data quality checks, lineage, access control, monitoring
Key questions: ownership, alerts, SLOs, audits
The “senior signals” to add (even in a junior-friendly job position)
- define SLAs: freshness, completeness, correctness
- define failure modes and what happens next
- plan backfills and reprocessing
- mention schema evolution strategy
Coding programs: ALL approaches + outputs
Program 1: Latest record per key (dedup)
Input
rows = [
{"user_id": 1, "ts": "2026-01-01T10:00:00", "val": "A"},
{"user_id": 1, "ts": "2026-01-01T10:00:00", "val": "B"},
{"user_id": 2, "ts": "2026-01-01T09:00:00", "val": "X"},
]
Assume ties broken by last occurrence in input.
Approach A: sort + overwrite dict (simple, O(n log n))
from datetime import datetime
def latest_per_user_sort(rows):
rows2 = sorted(rows, key=lambda r: (r["user_id"], r["ts"]))
out = {}
for r in rows2:
out[r["user_id"]] = r
return list(out.values())
Approach B: single pass with comparison (O(n))
def latest_per_user_one_pass(rows):
out = {}
for r in rows:
k = r["user_id"]
if k not in out or r["ts"] >= out[k]["ts"]:
out[k] = r
return list(out.values())
Expected output
[
{"user_id": 1, "ts": "2026-01-01T10:00:00", "val": "B"},
{"user_id": 2, "ts": "2026-01-01T09:00:00", "val": "X"},
]
Gotcha to say out loud: define tie-breaking and timestamp parsing rules.
Program 2: Flatten nested JSON
Input
doc = {"a": 1, "b": {"c": 2, "d": {"e": 3}}}
Approach A: recursion
def flatten_dict(d, prefix=""):
out = {}
for k, v in d.items():
key = f"{prefix}.{k}" if prefix else k
if isinstance(v, dict):
out.update(flatten_dict(v, key))
else:
out[key] = v
return out
Expected output
{"a": 1, "b.c": 2, "b.d.e": 3}
Gotcha: arrays and mixed types-clarify whether to explode or stringify.
Program 3: Top-K heavy hitters
Input
items = ["a","b","a","c","a","b"]
k = 2
Approach A: Counter (fast, O(n))
from collections import Counter
def topk_counter(items, k):
return Counter(items).most_common(k)
Approach B: dictionary + heap (good when unique is huge)
import heapq
def topk_heap(items, k):
counts = {}
for x in items:
counts[x] = counts.get(x, 0) + 1
heap = [(-c, x) for x, c in counts.items()]
heapq.heapify(heap)
return [(x, -c) for c, x in heapq.nsmallest(k, heap)]
Expected output
[("a", 3), ("b", 2)]
Gotcha: if streaming unbounded, mention approximate algorithms (Count-Min Sketch) to sound senior.
Program 4: SCD Type 2 + CDC MERGE
Scenario: You receive daily CDC updates: inserts/updates/deletes.
Approach (SQL MERGE conceptual)
- Match on business key
- If changed: expire current row, insert new version
- If delete: mark as deleted or expire row (policy decision)
Example pattern (pseudo-SQL; adapt per warehouse):
-- 1) Expire changed current rows
UPDATE dim_customer d
SET valid_to = c.change_ts, is_current = false
FROM cdc_customer c
WHERE d.customer_id = c.customer_id
AND d.is_current = true
AND c.op IN ('U')
AND (d.name <> c.name OR d.email <> c.email);
-- 2) Insert new versions
INSERT INTO dim_customer (customer_id, name, email, valid_from, valid_to, is_current)
SELECT customer_id, name, email, change_ts, NULL, true
FROM cdc_customer
WHERE op IN ('I','U');
Gotcha: handle “update with same values” or you’ll bloat history.
Comparison Table
| Method | Difficulty | Time Complexity | Best For |
|---|---|---|---|
| For/While loop (hash map) | Easy | O(n) | Latest-per-key dedup, fast ETL transforms |
| Recursion (divide & conquer) | Medium | O(n) | Showing recursion skills, nested structures |
| Sort + overwrite | Easy | O(n log n) | Simple explanation, moderate data sizes |
| Heap (nlargest) | Medium | O(n + m log k) | Top-K with many uniques and small k |
| Built-in libs (Counter, pandas normalize) | Easy | O(n) to O(n log k) | Clean readable solutions under time pressure |
| SQL MERGE / update+insert | Medium | Engine-dependent | SCD2 correctness, warehouse-native pipelines |
| Spark DataFrame merge | Medium–Hard | Distributed O(n) | Large-scale CDC/SCD processing |
Junior vs Senior: what different answers sound like
| Area | Junior passes when they… | Senior passes when they… |
|---|---|---|
| SQL | writes correct query | defines grain, edge cases, and performance |
| Python | solves problem | makes it idempotent + testable + memory-safe |
| Spark | knows transforms | predicts shuffles, skew, file sizing, AQE behavior |
| Airflow | can schedule | designs safe backfills + failure containment |
| Kafka | knows basics | reasons about event time, late data, replays |
| System design | draws boxes | defines contracts, SLAs, backfills, observability, cost |
Basics Questions
How do I explain a pipeline like a senior?
Input → contracts → transformations → output → SLA → quality checks → backfill strategy → cost levers.
What’s an idempotent pipeline?
Rerunning it produces the same final result without duplicates or double side effects.
What is CDC?
Change Data Capture: inserts/updates/deletes from a source system that must be applied correctly downstream.
What is SCD Type 2?
A modeling pattern that preserves historical versions of dimension attributes across time.
What causes Spark shuffles?
Wide operations like join, groupBy, distinct, orderBy, and repartition.
How do you handle data skew?
Salt hot keys, split hot partitions, use two-stage aggregation, or broadcast strategically.
What’s the difference between event time and processing time?
Event time is when an event occurred; processing time is when you processed it. Late events break naive processing-time logic.
Is exactly-once real?
It’s end-to-end semantics achieved with dedup keys + transactional sinks + careful replay handling.
What’s the grain of a table?
The single unit a row represents. Define it before modeling or querying.
FAQ
How do I prepare for a data engineer interview in 2026?
Master SQL windows + incremental loads, Python ETL patterns, and one distributed engine (Spark). Then drill system design with SLAs, backfills, and observability.
What should I study first for a data engineer interview?
Study SQL windows + dedup + incremental loading first. Then learn Python ETL patterns (idempotency, retries, memory). Then drill system design with SLAs and backfills.
How many questions should I practice?
Practice 30–50 high-quality problems across SQL, Python, and system design. Repeating a smaller set until you can explain edge cases beats collecting 300 links.
What’s the hardest part of DE interviews?
Edge cases and operational thinking: late data, retries, backfills, schema evolution, and cost.
How do I handle “unknown” questions in interviews?
Say what you know, ask clarifying questions, propose a safe default, and mention how you’d validate in production.
Conclusion+ 2026 learning roadmap (practical, not theoretical)
To master Data Engineer Interview Questions and Answers in 2026, prepare for both coding correctness and production thinking. Interviews reward candidates who can write clean SQL/Python and design systems that survive retries, backfills, schema changes, and real-world failures
- Week 1–2: SQL windows, dedup, sessionization, CDC/SCD2
- Week 3–4: Python ETL patterns, idempotency, tests, memory
- Week 5–6: Spark performance basics: shuffle, partitioning, skew
- Week 7: Airflow backfills + failure containment
- Week 8: Streaming semantics (event time, late arrivals, replays)
- Ongoing: system design drills using the 6-layer framework